文献来源:
Karan Singhal;Shekoofeh Azizi;Tao Tu;S. Sara Mahdavi;Jason Wei;Hyung Won Chung;Nathan Scales;Ajay Tanwani;Heather Cole-Lewis;Stephen Pfohl;Perry Payne;Martin Seneviratne;Paul Gamble;Chris Kelly;Abubakr Babiker;Nathanael Schärli;Aakanksha Chowdhery;Philip Mansfield;Dina Demner-Fushman;Blaise Agüera y Arcas;Dale Webster;Greg S. Corrado;Yossi Matias;Katherine Chou;Juraj Gottweis;Nenad Tomasev;Yun Liu;Alvin Rajkomar;Joelle Barral;Christopher Semturs;Alan Karthikesalingam;null;Vivek Natarajan.Publisher Correction: Large language models encode clinical knowledge[J].Nature,2023/WXFX_Large_language_models_encode_clinical_knowledge.pdf
文章摘要:
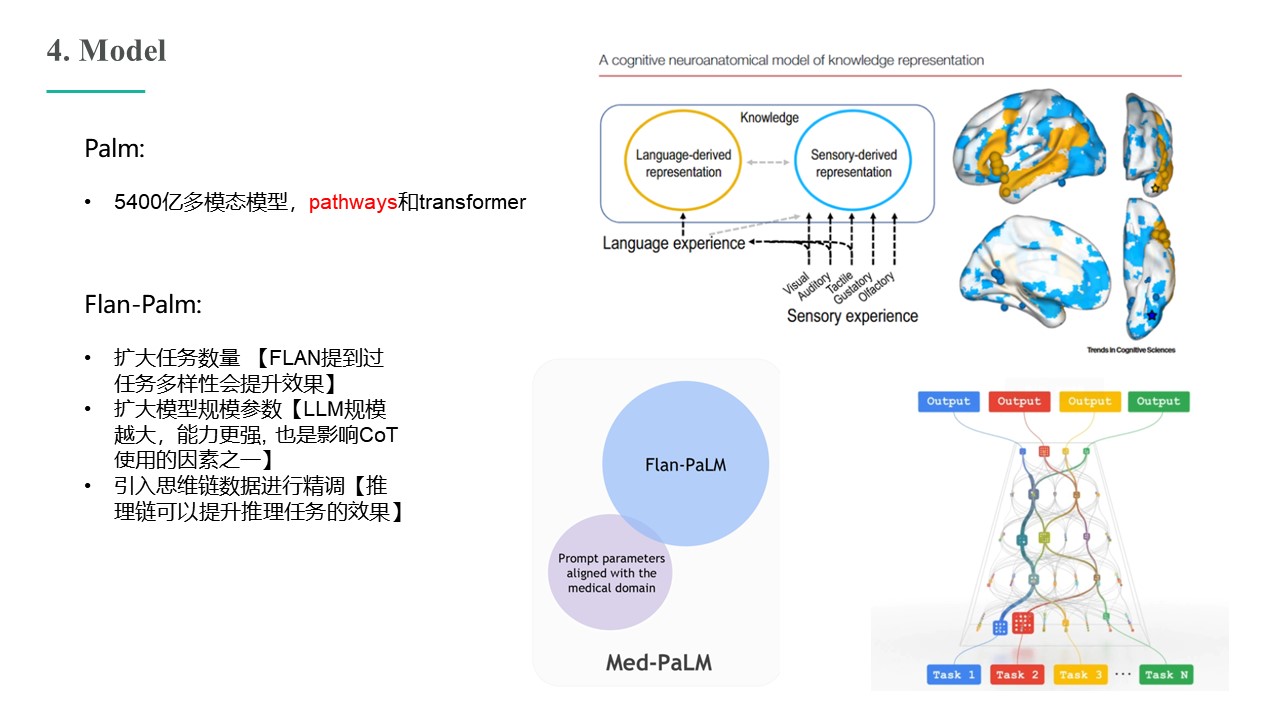
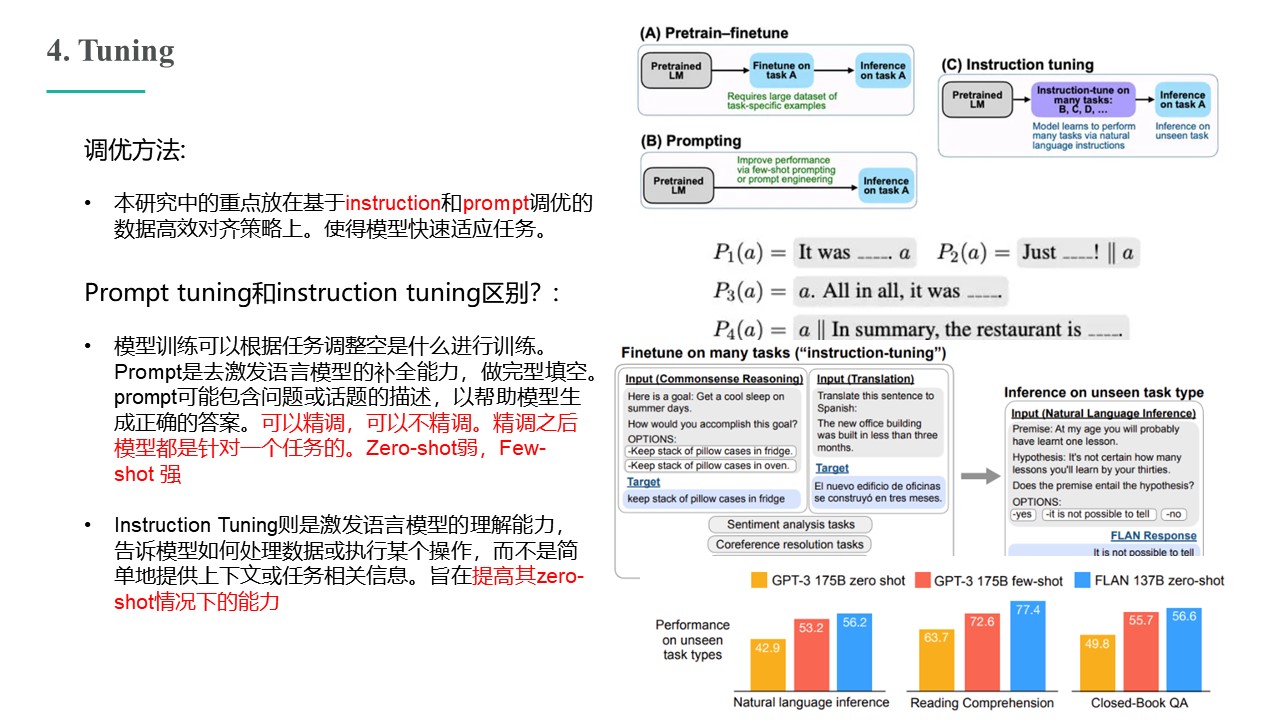
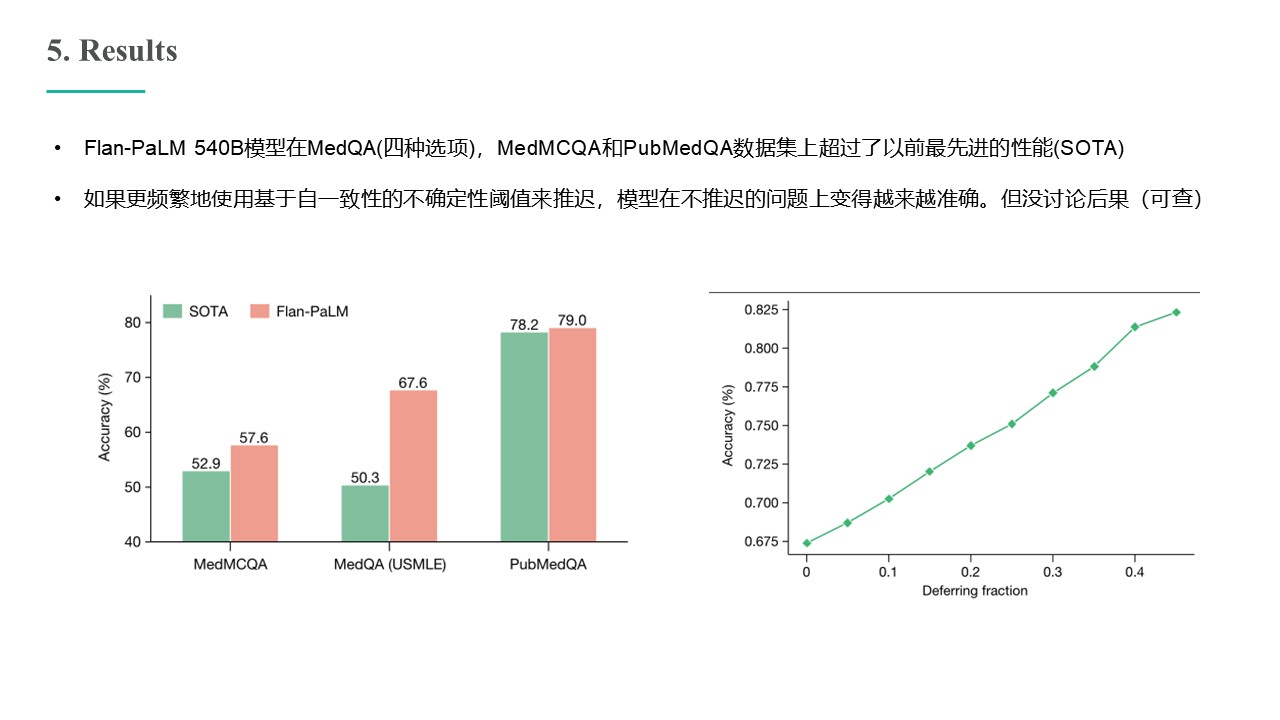
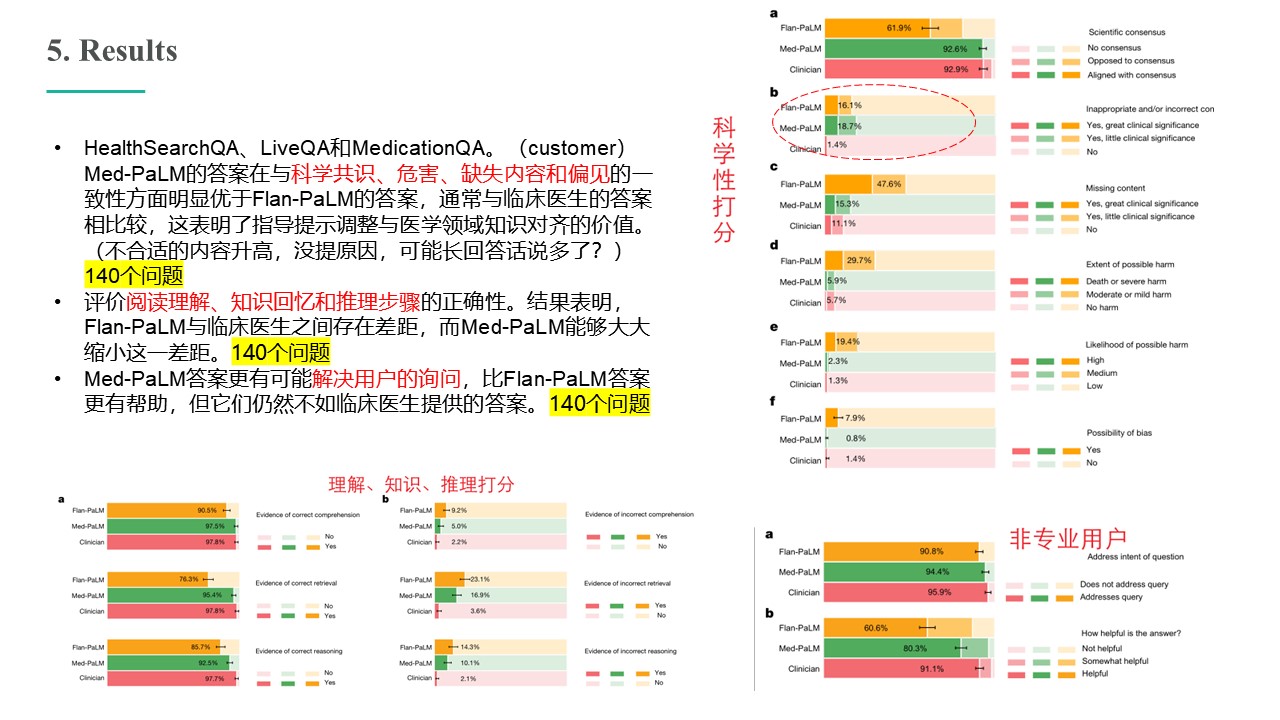
Large language models (LLMs) have demonstrated impressive capabilities, but the bar for clinical applications is high. Attempts to assess the clinical knowledge of models typically rely on automated evaluations based on limited benchmarks. Here, to address these limitations, we present MultiMedQA, a benchmark combining six existing medical question answering datasets spanning professional medicine, research and consumer queries and a new dataset of medical questions searched online, HealthSearchQA. We propose a human evaluation framework for model answers along multiple axes including factuality, comprehension, reasoning, possible harm and bias. In addition, we evaluate Pathways Language Model1 (PaLM, a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM2 on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA3 , MedMCQA4 , PubMedQA5 and Measuring Massive Multitask Language Understanding (MMLU) clinical topics6 ), including 67.6% accuracy on MedQA (US Medical Licensing Exam-style questions), surpassing the prior state of the art by more than 17%. However, human evaluation reveals key gaps. To resolve this, we introduce instruction prompt tuning, a parameter efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, knowledge recall and reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal limitations of today’s models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLMs for clinical applications.
分享内容:








声明:本网站内容版权归许鹏教授课题组所有。未经本课题组授权不得转载、摘编或利用其它方式使用上述作品。