文章摘要:Abstract
目前所有主流通用大模型(GPT-4、Gemini、Claude、Llama-3 等)在预训练阶段都没有把物理定律当作硬约束写进损失函数。
它们只是统计下一个 token 的概率”,所谓“物理”只是从海量文本里被动地“背”下了人类描述规律的句子,而不是主动遵守这些规律。
真正上线需要:
把暖通物理方程写进 attention mask(知识嵌入);
用暖通各个细分领域的数据做二次训练(领域对齐)
上述任何一项都不是“prompt engineering”能解决的,必须重训或增量训——这就已经是“暖通大模型”范畴。


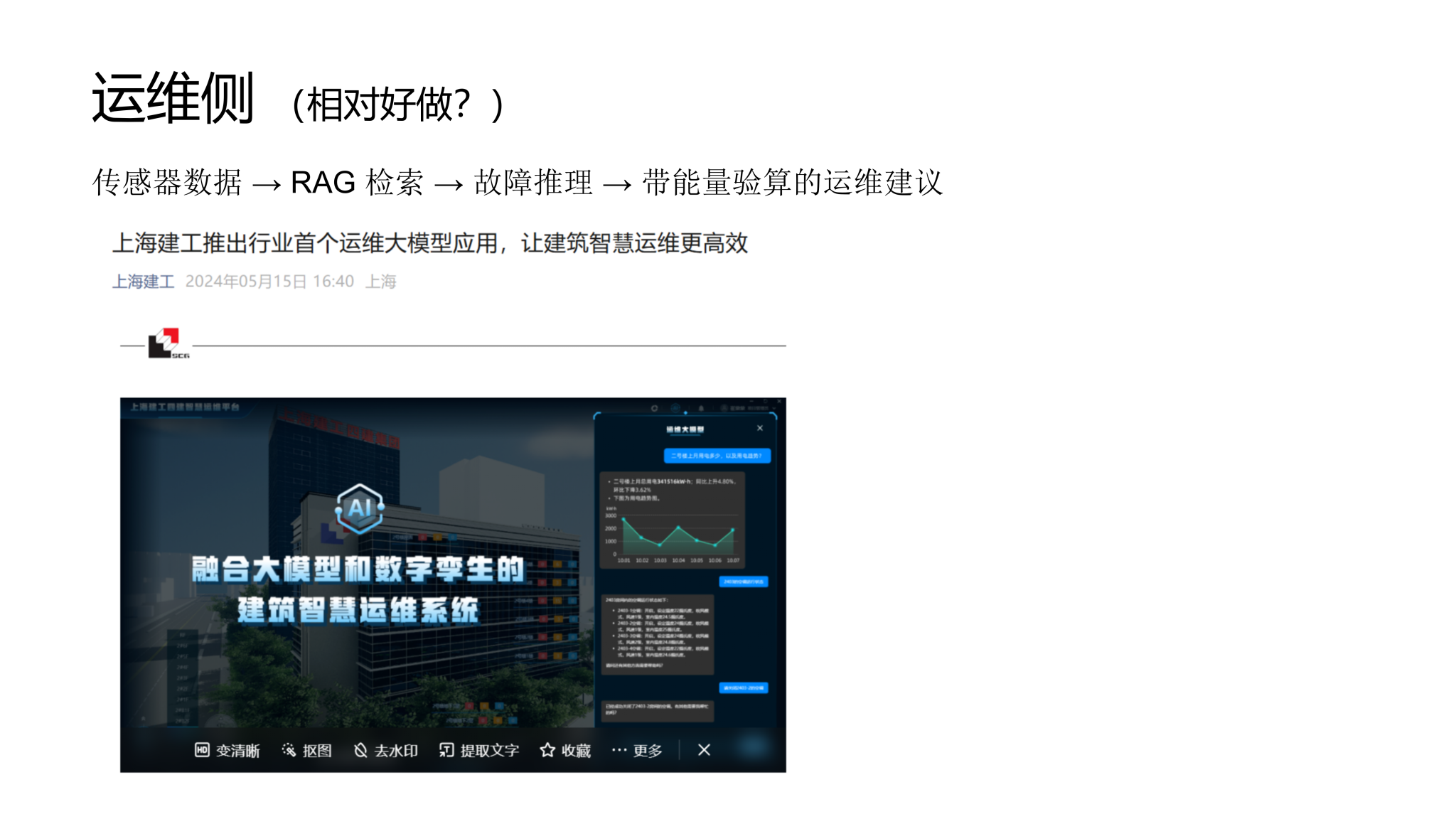


声明:本网站内容版权归许鹏教授课题组所有。未经本课题组授权不得转载、摘编或利用其它方式使用上述作品。